Abstract
Recent advances in vision-language models (VLMs) have significantly improved performance in embodied tasks such as goal decomposition and visual comprehension. However, providing accurate rewards for robotic manipulation without fine-tuning VLMs remains challenging due to the absence of domain-specific robotic knowledge in pre-trained datasets and high computational costs that hinder realtime applicability. To address this, we propose T2-VLM, a novel training-free, temporally consistent framework that generates accurate rewards through tracking the changes in VLM-derived subgoals. Specifically, our method first queries the VLM to establish spatially aware subgoals and an initial completion estimate before each round of interaction. We then employ a Bayesian tracking algorithm to update the completion status dynamically, using spatial hidden states to generate structured rewards for reinforcement learning (RL) agents. This approach enhances long-horizon decision-making and improves failure recovery capabilities with RL. Extensive experiments indicate that T2-VLM achieves state-of-the-art performance in two robot manipulation benchmarks, demonstrating superior reward accuracy with reduced computation consumption. We believe our approach not only advances reward generation techniques but also contributes to the broader field of embodied AI.
Method
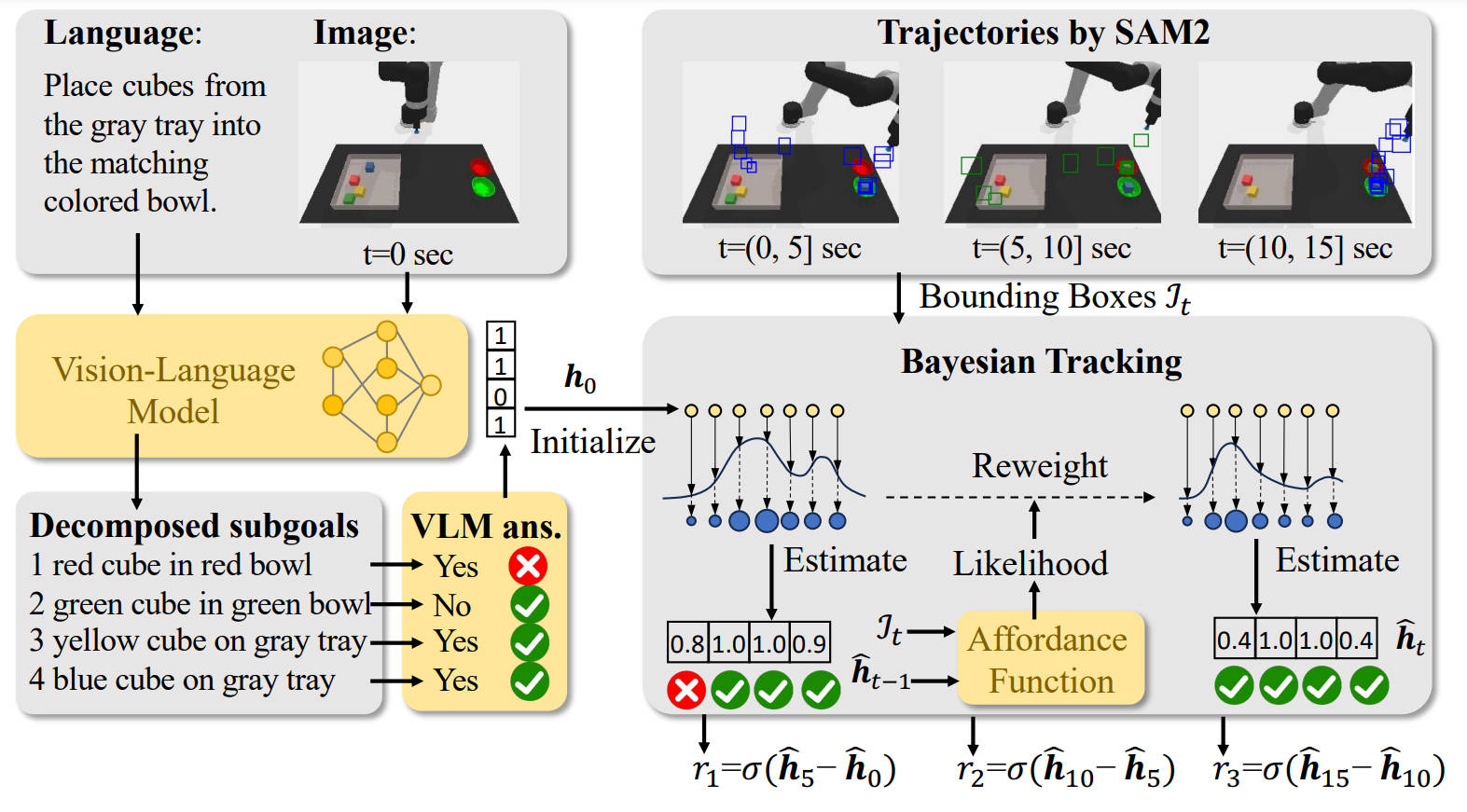
In this work, we introduce T2-VLM, a novel reward generation framework that ensures temporal consistency by tracking the environment's goal completion status. Fig. 2 provides an overview of T2-VLM. Unlike previous VLM-based reward generation methods, T2-VLM queries the VLM only once per episode, then incorporates temporal information (object trajectories) to update the VLM-initialized goal status. A Bayesian tracking algorithm is then proposed to manage the updates, enabling T2-VLM to remain training-free, deliver precise reinforcement learning (RL) rewards, and withstand inaccurate VLM estimations by leveraging temporal data.
Experiments
Compare T2-VLM and VLM-score on Place-same-color task.
T2-VLM
VLM-score
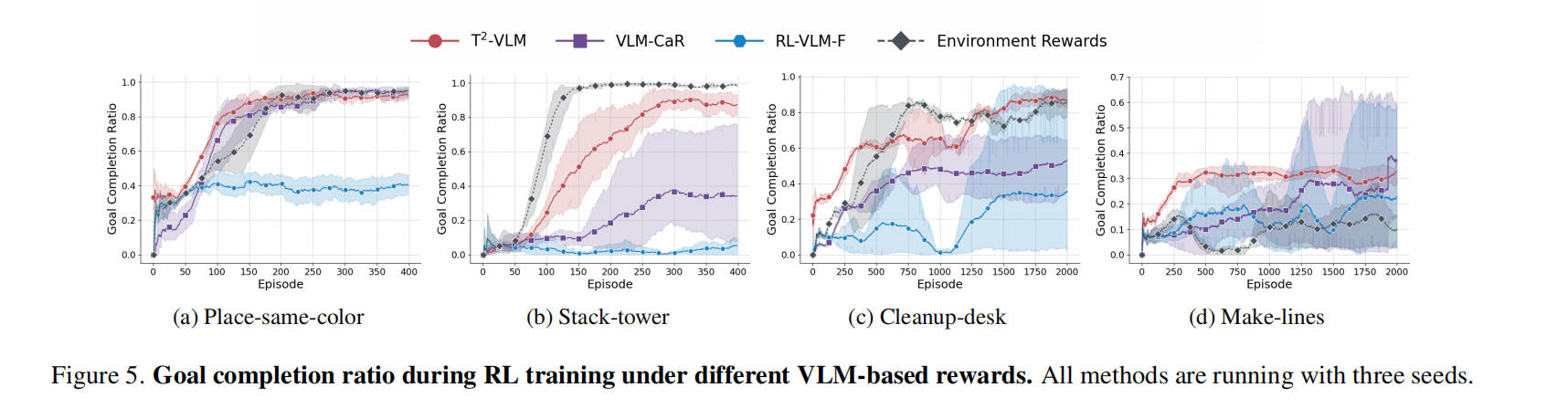
Compare T2-VLM and other reward generation methods on goal completion ratio.
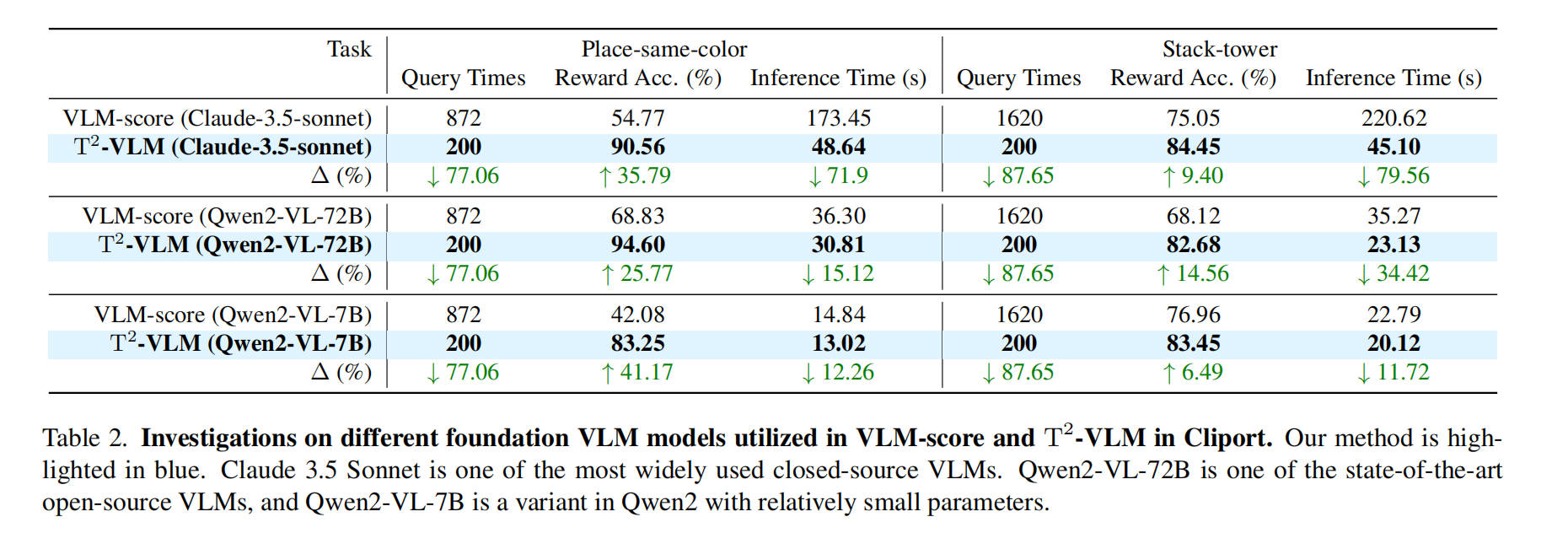
Compare T2-VLM and VLM-score under different VLM models.
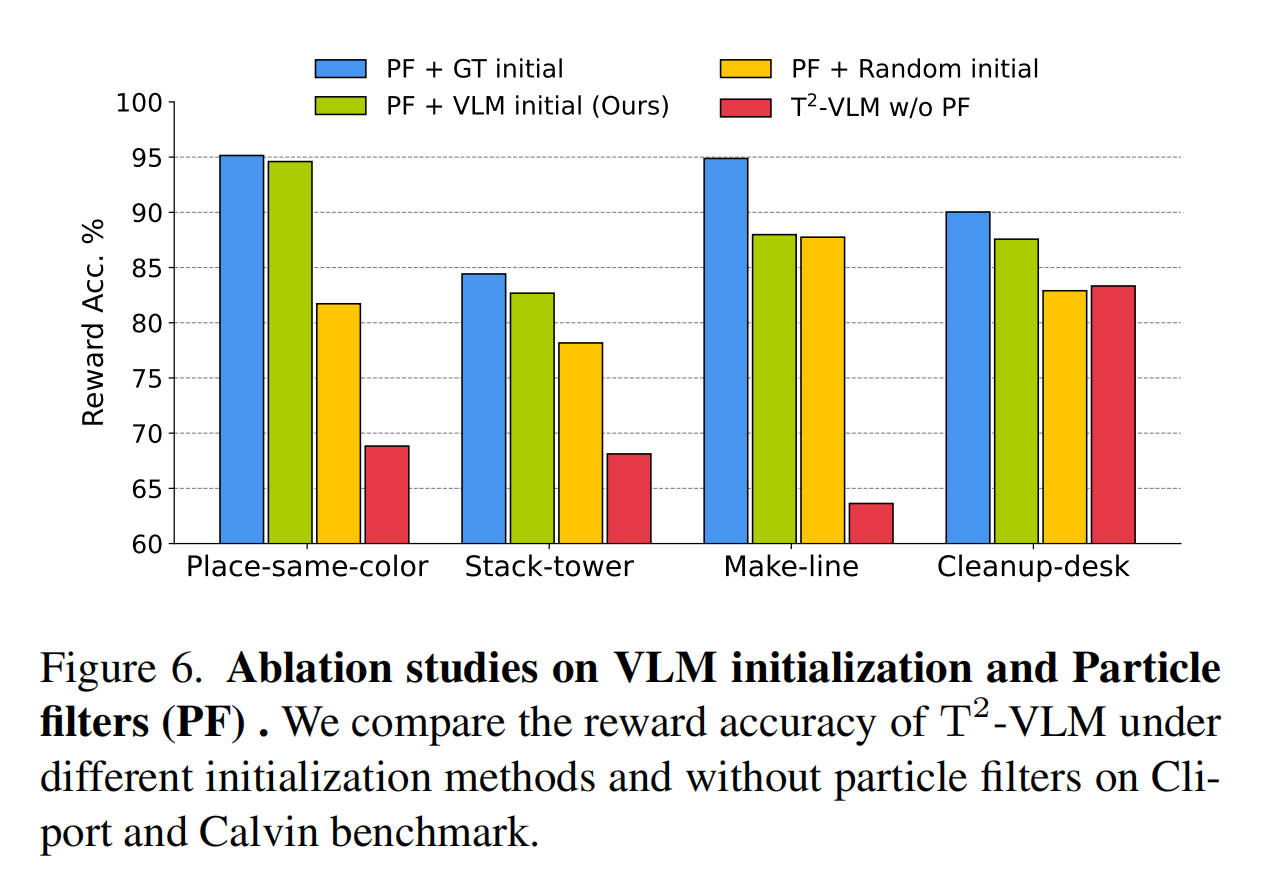
Ablation studies on VLM initialization and Particle filters.
Conclusion
Generating reliable and time-efficient rewards remains a major challenge in real-world robot manipulation tasks. In this paper, we propose T2-VLM, a Training-free Temporal-consistent reward generation method based on VLM-derived goal decomposition. In this work, we first introduce an automated procedure to prompt VLMs for decomposed subgoals and initial goal completion estimates before interaction, requiring only a single query per episode. Then, we encode these subgoal completion statuses into a scalar vector for particle filter initialization, allowing continuous updates based on temporal observations derived by SAM2. Experiments across three domains with six robot manipulation tasks show that the T2-VLM can well support the training of RL algorithms, offering high reward accuracy with lower computational cost.